※ 본 글은 김영한 님의 실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화 강의를 수강하고 작성한 글입니다.
[JPA] N+1 해결하기 를 통해 N+1 문제를 해결하는 방법을 다뤘었는데, ~ToOne인 경우만 다뤘습니다.
~ToOne인 경우엔 fetch join을 통해 N+1 문제를 해결할 수 있지만, OneToMany 관계에서는 fetch join 만으로 해결할 수 없습니다.

위와 같이 엔티티가 관계를 맺고 있을 때, Team의 목록을 불러오는 코드를 통해 문제상황과 해결책을 살펴보겠습니다.
전체 코드는 깃허브에 공유해두었습니다!
1. Fetch join의 문제점
먼저 ToOne 관계에서 했던 것처럼, fetch join을 한번 사용해보겠습니다.
public List<Team> getTeams_v1(){
return em.createQuery(
"select t from Team t" +
" join fetch t.members m" +
" join fetch m.locker l"
)
.getResultList();
}이런 코드가 되겠죠.
t.member를 그냥 fetch join하고, 또 member와 1:1 관계인 locker까지 fetch join 해옵니다.
언뜻 보면 N+1을 예방하면서, 쿼리 한번으로 문제없이 동작할 것 같습니다.
실행에 앞서 먼저 데이터를 넣어보겠습니다.
팀 1, 팀 2 두 개의 팀을 만들고, 각각 회원1-1, 회원 1-2와 회원 2-1, 2-2를 추가해주었습니다.
또 각가의 회원에게는 1-1~2-2 회원에게 각각 100~400의 번호를 갖는 라커를 할당해준 상태입니다.
즉, 전부 join 해서 DB를 확인해보면 다음과 같은 상태입니다.

이 상태에서 위 코드(v1)을 실행해보면 어떻게 될까요?
한번 실행 시켜보겠습니다.
[
id: 1
name : 팀 1
members :
[id: 1/name : 회원1-1/locker-number : 100, id: 2/name : 회원1-2/locker-number : 200]
,
id: 1
name : 팀 1
members :
[id: 1/name : 회원1-1/locker-number : 100, id: 2/name : 회원1-2/locker-number : 200]
,
id: 2
name : 팀 2
members :
[id: 3/name : 회원2-1/locker-number : 300, id: 4/name : 회원2-2/locker-number : 400]
,
id: 2
name : 팀 2
members :
[id: 3/name : 회원2-1/locker-number : 300, id: 4/name : 회원2-2/locker-number : 400]
](보기 좋게 toString을 오버라이딩한 상태입니다.)
분명 팀을 2개 넣었는데, 총 4개의 데이터가 출력되는 것을 확인할 수 있습니다.
자세하게 살펴보면, team 데이터의 정보는 맞지만, 중복돼서 출력되고 있습니다..
이런 일이 발생하는 이유는 위 join 결과를 다시 한번 살펴보면 알 수 있습니다.
OneToMany 관계에서는 출력되는 row 수가 늘어날 수 밖에 없습니다. 결과가 이렇다보니, JPA 입장에서는 해석이 애매하고, List<Team>에 row 수만큼 4개 넣어주는 것이죠.
2. distinct 사용하기
JPA가 데이터를 어떻게 뿌려주는 것인지 애매해서 저렇게 동작한다면, 조금 더 명확하게 표현을 해주면 됩니다.
바로 아래와 같이, JPQL에서 distinct 키워드를 추가해주는 것입니다.
public List<Team> getTeams_v2(){
return em.createQuery(
"select distinct t from Team t" +
" join fetch t.members m" +
" join fetch m.locker l"
)
.getResultList();
}
SQL에서 distinct를 추가하는 것과 비슷한 효과로, 똑같은 id를 같는 엔티티의 중복을 예방해주는 것입니다.
(실제로 SQL 자체에도 distinct를 붙이기도 하지만, SQL의 distinct만 추가하는 것과는 다릅니다!)
바로 distinct를 추가한 getTeams_v2를 실행한 결과를 살펴보겠습니다.
[
id: 1
name : 팀 1
members :
[id: 1/name : 회원1-1/locker-number : 100, id: 2/name : 회원1-2/locker-number : 200]
,
id: 2
name : 팀 2
members :
[id: 3/name : 회원2-1/locker-number : 300, id: 4/name : 회원2-2/locker-number : 400]
]이제 중복없이 데이터가 원하는 형태로 조회되는 것을 확인할 수 있습니다!
그런데 여기서 끝이 아닙니다!
Distinct를 활용한 방식에는 치명적인 단점이 존재하기 때문에, 사실상 활용이 어렵습니다.
바로 페이징이 불가능하다는 점입니다.
이 방식은 join 방식을 활용에 ToMany 관계인 데이터를 한번에 조회하는 방식의 근본적인 한계입니다.
다시 DB에서 join한 형태를 보겠습니다.
애초에 이 구조에서 페이징이 불가능합니다.
페이징이라는건 결국 offset과 limit를 정하는 것인데, Team을 기준으로 offset을 정할 수도 없고 limit를 정할 수도 없습니다.
ToMany 관계인 엔티티의 수에 따라 row의 번호가 결정되기 때문이죠.
지금은 각 팀별로 회원의 수가 딱 2개가 되도록 데이터를 넣었기 때문에 언뜻보면 페이징이 가능할까 싶지만, 팀 별로 멤버의 수가 달라진다고 하면 offset과 limit를 정할 수 없겠죠.
(※ 사실 페이징이 지원은 됩니다. 우선 모든 리스트를 메모리에 올린다음에, 리스트에서 페이징하는 방식으로 지원됩니다. 엄청나게 비효율적이고 또 아웃오브메모리까지 발생할 수 있으니 그냥 사용하지 않으면 됩니다!)
3. 해결책
Fetch join은 불가능하지만 여전히 OneToMany 관계에서도 N+1 문제를 해결할 수 있습니다.
바로 'spring.jpa.properties.hibernate.default_batch_fetch_size' 설정을 이용하면 됩니다.
default_batch_fetch_size에 대한 설명을 먼저 보겠습니다.

'N+1 문제를 예방하기 위해, lazy fetch할 연관관계를 batch로 fetch한다.'
지금의 Team Member 예제를 기준으로 설명하면 다음을 의미합니다.
1. default_batch_fetch_size 사용 X
List를 조회하면 N개의 Team 마다 List를 조회해야되기 때문에, N개의 쿼리가 더 발생한다(N+1문제)
즉, 각 팀마다 Member를 lazy loading 시점에서,
select * from member where id = 1
..
select * from member where id = 4,
2. default_batch_fetch_size 사용
--> 지연로딩이 필요할 때마다 default_batch_fetch_size만큼 묶음으로 미리 조회
즉, Team 1을 lazy loading하는 시점에서,
select * from member where id in (1, 2, 3, 4) 쿼리 한번만 실행.
결론적으로 1 + N 문제를 1 + 1 문제로 바꿀 수 있습니다!
사실 정확히는 1 + O(1)이 더 맞겠네요. 데이터의 수가 default batch fetch size 보다 크다면, select 쿼리가 더 필요하긴 합니다.
이제 코드로 확인해보겠습니다.
public List<Team> getTeams_v3(){
return em.createQuery(
"select t from Team t"
)
.getResultList();
}먼저 jqpl은 매우 간단해집니다. 지연로딩을 이용할 것이므로, Team만 읽어오면 됩니다.
다음으로 getTeam_v3를 호출하고 팀 목록을 조회하면 다음과 같이 쿼리가 발생합니다.
(1) Team 목록 조회

먼저 Team 목록을 조회합니다. 이때 Member를 join 하지 않습니다.
(2) Member 목록 조회

다음으로 Team에 대한 정보를 출력할 때, 지연로딩이 발생하면서 Member를 조회합니다.
이때 N번 조회하는 것이 아니라 'in'을 이용해서 딱 1번만 조회합니다.
in에 들어가는 기준이 궁금해서 찾아본 결과, 다음과 같이 설명되어 있습니다.
The primary key values to batch fetch are chosen from among the identifiers of unfetched entity proxies or collection roles associated with the session.
설명이 조금 애매하긴 한데, in 절에는 현재 lazy loading을 기다리고 있는 Team의 id 목록인 1과 2가 들어가게 됩니다.
(3) Locker 조회
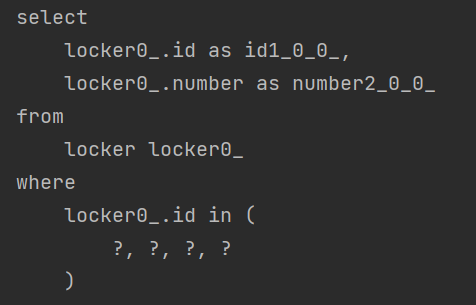
아직 끝이 아니라, Member와 1:1 관게인 Locker 도 로딩해주어야 합니다.
따라서 이에 대한 지연로딩 쿼리가 필요하고, 이때에도 default_batch_fetch_size를 설정한 것이 유효하므로 지연 로딩을 기다리고 있는 Member의 id 목록인 1, 2, 3, 4가 in 절에 들어갑니다.

마지막으로 출력 결과입니다. 원하는 형태로 데이터가 잘 출력되었네요.
4. 주의사항
default_batch_fetch_size, 지연로딩을 이용할 때 2가지 정도 주의할 점이 있습니다.
(1) OSIV
OSIV 에 대해서는 기회가 되면 따로 정리하고 간단하게 정리하겠습니다.
당장 프로젝트에 적용하실 계획이라면 꼭 잘 알아보고 적용하시면 됩니다.
Open session in view의 약어로, 이 옵션이 켜있으면 한 요청에 대해서는 @Transactional 밖에서도 지연로딩이 가능하고, OSIV가 꺼져있으면 @Transacional 밖에서 지연로딩이 불가능합니다.
OSIV 를 키면 하나하나의 요청이 데이터베이스 커넥션을 오래 사용하므로, 장애가 발생할 수 있습니다.
따라서 웬만하면 끄는 것이 좋고, 이때 필요한 지연로딩을 모두 @Transactional 안에서 처리하도록 주의해야 합니다.
(2) batch size 설정
Batch size는 사실 클수록 추가 쿼리가 발생하지 않을 확률이 크기 때문에 좋긴 하지만, 우선 DB in 절의 제약때문에 1000을 안넘기는 것이 좋습니다.
따라서 1000이하에서 크게 설정하면 좋고, 너무 크면 DB나 서버에 무리가 갈 수 있으므로, 이에 주의해야합니다.
결론
- OneToMany 관계에서는 fetch join으로 N+1을 해결할 수 없다.
- spring.jpa.properties.hibernate.default_batch_fetch_size 옵션을 이용하자
- 대신 OSIV 설정에 유의하고, batch size 설정도 잘 고려하자
'JPA' 카테고리의 다른 글
| [JPA] default_batch_fetch_size 동작 (0) | 2023.04.12 |
|---|---|
| [JPA] 동적쿼리, QueryDSL (0) | 2023.04.07 |
| [JPA] N+1 문제 해결하기 (0) | 2023.04.05 |
| [JPA] 즉시로딩, 지연로딩 (0) | 2023.03.29 |



